











【SQL Server】実行計画を見てみよう
1. はじめに
こんにちは、エンジニアの末武です。
今回はSQLserverの実行計画の見方についてお話します。
システムを作った経験のある方なら、一度は必ずデータベース周りの遅延やパフォーマンス周りに頭を抱えた経験があるのではないでしょうか。
データベース周りの悲鳴が止むことはありませんが、SQLがどのようにデータベースのストレージやメモリにアクセスしているのかを示してくれる実行計画の見方を知ることは、それに対抗する手段として非常に有用です。
それでは早速SQLserverの実行計画を見ていきましょう!
2. 実行計画って何、どうやって見るの?
実行計画とは、SQLserverがユーザーが発行したSQLを解析し決定した実データに対して、どのようにアクセス・計算を行うかが記載されている計画書です。
SQLはDBの「どの」データを取得するかをユーザーが指定しますが、「どのように」そのデータを探して取得するかはSQLserverのオプティマイザ機構が決定します。それが実行計画です。
実行計画の見方は、SQLServer Management Studio(SSMS)の機能によるグラフィカルな表示と、テキストでの表示があります。
グラフィカルな実行プランを表示する場合は、SSMSのクエリ実行画面にて、「実際の実行プランを含める」オプションをONにした状態でクエリを実行します。すると結果セットに「実行プラン」タブが表示され、グラフィカルな実行プランの経路図が見られます。
※画像の実行プランは、インデックスの存在しないテーブルへ単純なSelect文を発行した実行計画です。
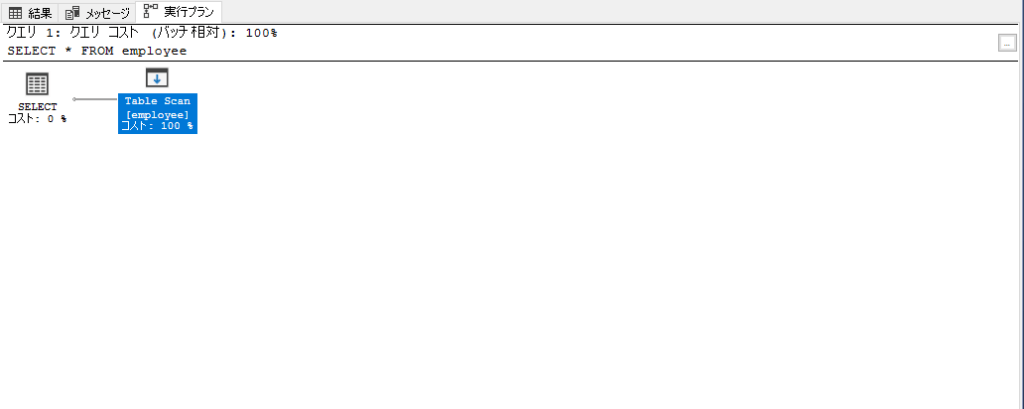
アイコンはデータを取得するためのSQLserverのアクションのひとつを示しており、結合などで複数テーブルにアクセスする場合は枝分かれし、最終的にひとつの結果セットを出力します。(処理順は右から左、上図の場合は「Table Scan」が行われた後に「Select」が実行されます)
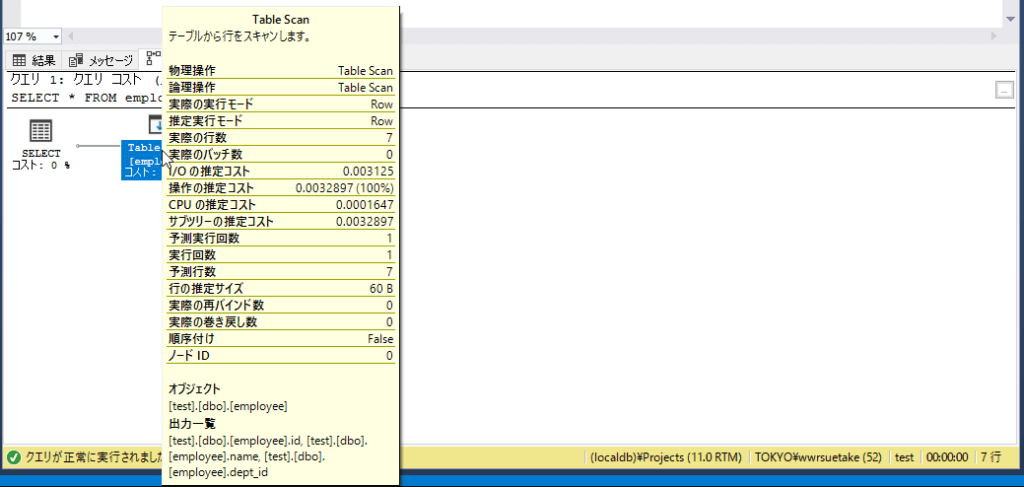
アイコンをマウスオーバーするかクリックすると、アクションのプロパティを見ることができます。
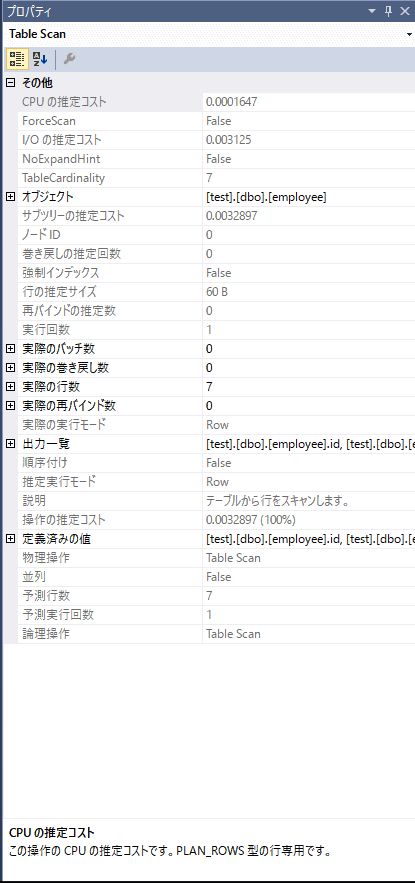
プロパティには、かかっているコストや実行時間、操作しているテーブルと出力しているデータの情報が含まれており、パフォーマンスのチューニングに活用できます。
テキストベースの実行プランを出力する場合は、SQLの実行時に以下のように「SET STATISTICS PROFILE ON」文を追加します。
SET STATISTICS PROFILE ON
SELECT * FROM employee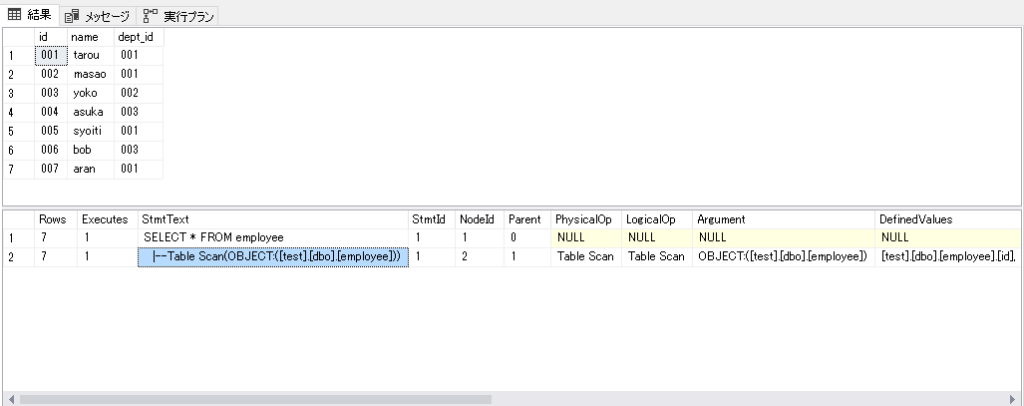
表示形式は違いますが、取得できる情報はテキストベースもグラフィックベースも同じなので、見やすい方で取得して問題ありません。
3. テーブルアクセス
続いて、実行プラン表示のアクセスを表す各アイコンをそれぞれ説明します。
テーブルアクセスのためのアイコンは実行計画の末尾に必ずあり、どのテーブルへどのようなアクセス方法でデータを取得するのかを示します。
Table Scan

インデックスを全く使用せず、ヒープにあるデータへのアクセスを示します。
テーブルアクセス系には、以下の2種類があります。
・Scan:対象を全件走査する
・Seek:二分木探索でデータを捜索する
基本的にインデックスが使われていれば速い「Seek」になります。一方で、「Table Scan」はテーブルアクセスの中で最も遅い処理です。
クラスタ化インデックスが張られていないテーブルに対して「Where条件無しか、インデックスが張られていないカラムを条件に」抽出を行うとこのようになります。
Index seek

インデックスに対する二分探索を行うテーブルアクセスです。
検索条件にインデックスが貼られたカラムを指定するとこれになり、データを全件走査するのではなくインデックスに対して二分木探索を行うので高速です。
Index Scan

IndexなのにScanなの? と混乱しそうになりますが、内容としては「インデックスに対して全件走査を掛ける」ということです。
インデックスが貼られたカラムのみをSelectで出力したりするとこちらが出てきますが、あまり見ないので気にしないです。
Clusterd Index Scan

クラスタ化インデックス領域に対して全件走査を掛けるアクションです。
上記の「Index Scan」は、(NonClustered)と書かれている通り、あちらは「非クラスタ化インデックス」に対してのアクションになります。
クラスタ化インデックスを使用はしていますが、実際は全てのデータに対して走査をかけているので、性能は「Table Scan」に近く低速です。
クラスタ化インデックスが張られているテーブルに対して「Where条件無しか、インデックスが張られていないカラムを条件に」抽出を行うとこれになります。
クラスタ化インデックス シーク

どうして日本語なのか不思議ですが、、、英語表記では「Clustered Index Seek」です。
クラスタ化インデックスに対して二分木探索を行いますので、Index Scanと同様に高速です。
クラスタ化インデックスカラムに対しての条件指定での抽出を行うとこれになります。
4. 結合
結合句やサブクエリにより、複数のテーブルへのアクセスをしたときに一つのデータに纏める際のアクションです。
オプティマイザがデータ分布を解析し、「Nested Loop」「Hash Match」「Merge Join」の中で最適なものを選択します。
Nested Loops

二つのテーブルを二重ループで結合するものです。
基本はこれが使用されます。
Hash Match

結合キーに対してハッシュ関数を使用してハッシュテーブルを作成し、相手のテーブルの結合キーにハッシュ値が存在するかを調べます。
Nested Loopsが有効でない場合に選択されることがありますが、メモリを多く消費するのでパフォーマンスが落ちる可能性があります。
Merge Join
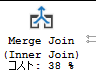
結合キーによって結合対象テーブルをソートし、キーに含まれていたら結果セットに対象行を含めます
5. キー参照
Where句にインデックス対象行が指定され、Select句にインデックス以外のカラムが指定された場合、Index Seekによる二分木探索が行われた後に足りないデータを探しにキー参照が行われます。
クラスタ化インデックスが張られているかによって以下の二種類のどちらかが実行され、インデックスで取得したデータに結合されます。
Index Seekが行われているのに遅い原因の一つになり得、インデックス以外の列が不要であればSelect句から外すなどでこのキー参照を行わないようにすることが可能です。
RID Lookup
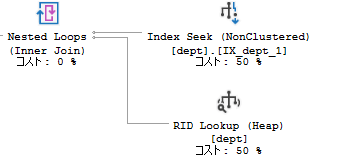
クラスタ化インデックスが張られていないテーブルに対して使われるキー参照です。
インデックスのリーフノードに格納された、データを一意に識別するための「RID」によりヒープ領域(テーブルの実データが格納されている)に対象行のデータを取得しにいきます。
キー参照(Clustered)
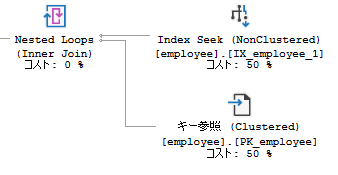
クラスタ化インデックスが張られているテーブルに対して使われるキー参照です。
クラスタ化インデックスを使用して対象行のデータを取得しにいきます。
6. 述語
ここではインデックスが正常に使用されているかを判断する一つの要素として、プロパティの述語について記載します。
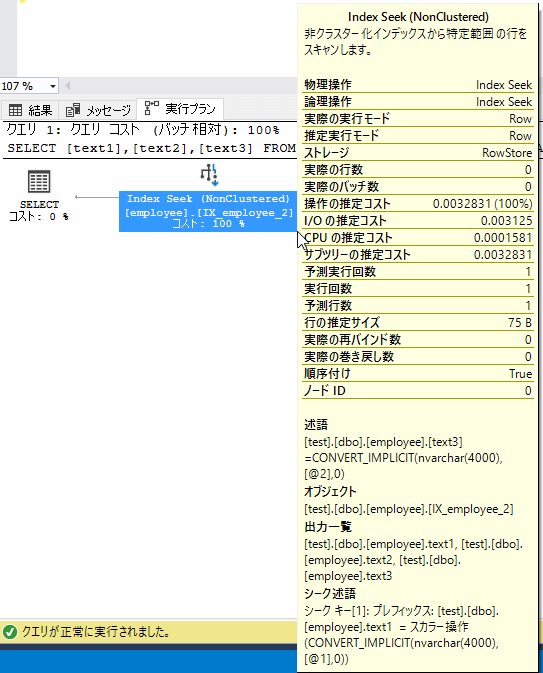
上記画像は以下のクエリの実行計画の「Index Seek」アクションのプロパティを表示したものです。
テーブル「employee」には「text1,text2,text3」をキーにした複合インデックスが張られています。
SELECT text1, text2, text3
FROM employee
WHERE text1 = 'aaa'
AND text3 = 'bbb'プロパティの表記は最上段が「アクションの種類と説明」中段が「パフォーマンス情報」下段が「操作対象のオブジェクトと出力結果」です。
中段はクエリに対するコストなどが見られるので、ここを見てチューニングを行い、コストが下がることを目指します。
下段に「述語」と「シーク述語」がありますが、このうち「述語」に表記されている条件(この場合は「text3=’bbb’」)はインデックスの恩恵を得られていません。
text3は複合インデックスに含まれていますが、text2による指定がないので複合インデックスが最大限働いていないのです。
このような場合、新たにインデックスを追加したり(text1,text3の複合インデックス等)、抽出条件を再考することでパフォーマンスの改善の余地があります。
Index Seekだけでなく、Where句や結合が行われた場合テーブルアクセスのアクションのプロパティに条件での「述語」もしくは「シーク述語」が表示されており、「述語」に条件が表記されていれば、チューニングの余地があります。
7. 統計情報との関係
実行計画を作る時にオプティマイザがデータ分布の参考として用いるのが統計情報で、統計情報が古いとSQLのパフォーマンスが落ちるのは、過去のデータ分布に対して最適な実行計画が今のデータ分布には最適でないことがあるからです。
統計情報のデータ分布が古いと、インデックスが使用されなかったり効率の悪いインデックスが使用されてり、パフォーマンスの悪い結合が行われることがあります。
パフォーマンスが悪いSQLを発行してしまっている場合はもちろん、上記のような統計情報が古いことにより最適化が正常に行われていないことを検知するためにも、実行計画を読み解くことは有用な手段です。
8. おわりに
SQLServerの実行計画の見方について書きましたが、専門知識が非常に多く私自身触り程度しか理解できていないと改めて感じました。
ただ実行計画を理解することで、感覚的に理解していたSQLのデータへのアクセス経路をより具体的に考えることができるようになることは間違いありませんので、実行計画に触れてこなかった方は一度触れてみてはいかがでしょうか?