











Kagglerへの道#2 Mercari Price Suggestion Challenge:メルカリ価格提案チャレンジ
1. はじめに
皆さん、おはこんばんにちは! SIer出身のエンジニア、みやもとです。
前回はKaggleのチュートリアルであるタイタニック問題にチャレンジしました。前回のタイタニック問題ではグラフなどを使用してデータセットを可視化できなかったため、それも含めてチャレンジしていこうと思います。
今回は「Mercari Price Suggestion Challenge」(メルカリ価格提案チャレンジ)をやってみたいと思います。
2. メルカリ価格提案チャレンジとは
Kaggleメルカリチャレンジでは、販売者が投稿した情報を基に「適正な販売価格」を予測するチャレンジです。訓練データとして、ユーザーが投稿した商品情報やカテゴリ、さらに商品の状態やブランド名などが与えられており、それらを基に販売価格を予測するモデル作成が課題です!
3. 事前準備
データセットの確認
まずは、必要なpandasやsklearnなどをインポートします。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
from sklearn.model_selection import train_test_split
pd.set_option('display.float_format', lambda x:'%.3f' % x)
import numpy as np
import matplotlib.pyplot as plt
■トレーニングデータセット
train = pd.read_csv('/ディレクトリパス/train.tsv', delimiter='\t', low_memory=True)
train.head()
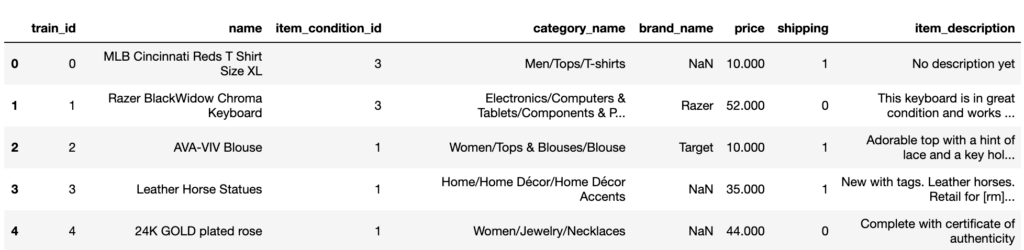
〇train_id:ユーザー投稿のID
〇name:投稿のタイトル
〇item_condition_id:ユーザーが指定した商品の状態
〇category_name:投稿カテゴリー
〇brand_name:ブランド名
〇price:実際に売られた価格
〇shipping:送料のフラグ 「1」は販売者負担、「0」は購入者負担。
〇item_description:ユーザーが投稿した商品説明の全文
■テストデータセット
test = pd.read_csv('/ディレクトリパス/test.tsv', delimiter='\t', low_memory=True)
test.head()

〇test _id:ユーザー投稿のID
〇name:投稿のタイトル
〇item_condition_id:ユーザーが指定した商品の状態
〇category_name:投稿カテゴリー
〇brand_name:ブランド名
〇shipping:送料のフラグ 「1」は販売者負担、「0」は購入者負担
〇item_description:ユーザーが投稿した商品説明の全文
# trainの基本統計量を表示
train.describe(include='all').transpose()
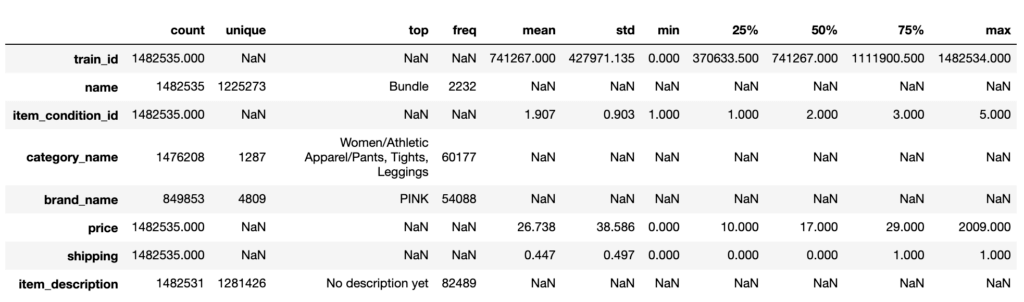
〇count:要素の個数
〇unique:ユニークな(一意な)値の要素の個数
〇top:最頻値(mode)
〇freq:最頻値の頻度(出現回数)
〇mean:算術平均
〇std:標準偏差
〇min:最小値
〇max:最大値
〇50%:中央値(median)
〇25%、75%:1/4分位数、3/4分位数
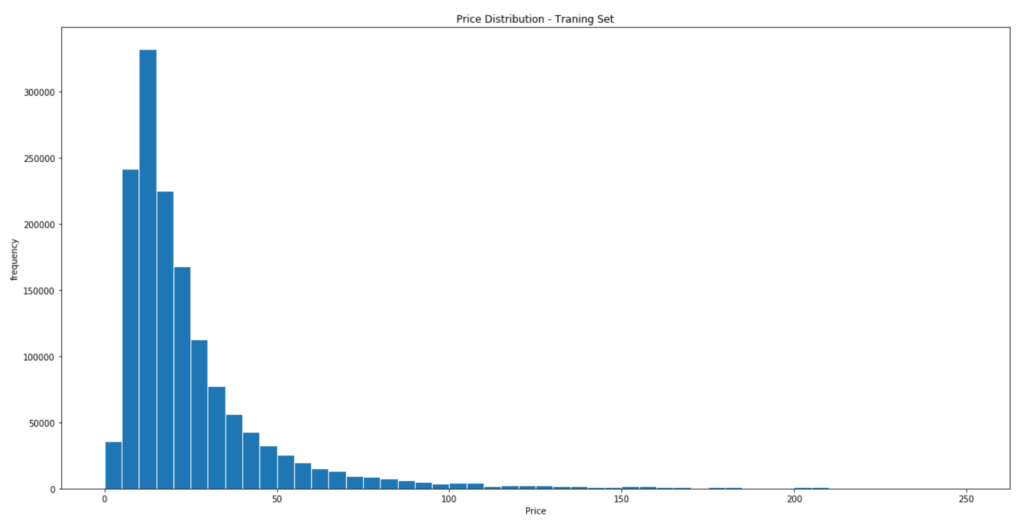
■Price(価格)
trainのPriceをヒストグラムで表示してみるとPriceは0〜50の間が多いことが分かります。データセットはヒストグラムなどにするととても分かりやすいです。
# trainのPriceをヒストグラムで表示
train['price'].plot.hist(bins=50, figsize=(20, 10), edgecolor='white', range=[0, 250])
# タイトル
plt.title(‘Price Distribution – Traning Set’)
# x軸のタイトル
plt.xlabel(‘Price’)
# y軸のタイトル
plt.ylabel(‘frequency’)
欠損値の確認
次に欠損値の確認を行います。
train.info()
print('_'*40)
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1482535 entries, 0 to 1482534
Data columns (total 8 columns):
train_id 1482535 non-null int64
name 1482535 non-null object
item_condition_id 1482535 non-null int64
category_name 1476208 non-null object
brand_name 849853 non-null object
price 1482535 non-null float64
shipping 1482535 non-null int64
item_description 1482531 non-null object
dtypes: float64(1), int64(3), object(4)
memory usage: 90.5+ MB
________________________________________
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 693359 entries, 0 to 693358
Data columns (total 7 columns):
test_id 693359 non-null int64
name 693359 non-null object
item_condition_id 693359 non-null int64
category_name 690301 non-null object
brand_name 397834 non-null object
shipping 693359 non-null int64
item_description 693359 non-null object
dtypes: int64(3), object(4)
memory usage: 37.0+ MB
欠損値の補完とデータの変換
今回は、Price(価格)をターゲットに予測を行うためデータの変換を行っていきたいと思います。
# trainの「カテゴリ名」「商品説明」「投稿タイトル」「ブランド名」のデータタイプを「category」へ変換
train.category_name = train.category_name.astype('category')
train.item_description = train.item_description.astype('category')
train.name = train.name.astype('category')
train.brand_name = train.brand_name.astype('category')
# testの「カテゴリ名」「商品説明」「投稿タイトル」「ブランド名」のデータタイプを「category」へ変換
test.category_name = test.category_name.astype(‘category’)
test.item_description = test.item_description.astype(‘category’)
test.name = test.name.astype(‘category’)
test.brand_name = test.brand_name.astype(‘category’)
# trainとtestのidカラム名を変更
train = train.rename(columns = {'train_id':'id'})
test = test.rename(columns = {'test_id':'id'})
# 両方のデータセットへ「is_train」のカラムを追加
# 1 = trainのデータセット、0 = testデータセット
train[‘is_train’] = 1
test[‘is_train’] = 0
# trainのprice以外のデータをtestと連結
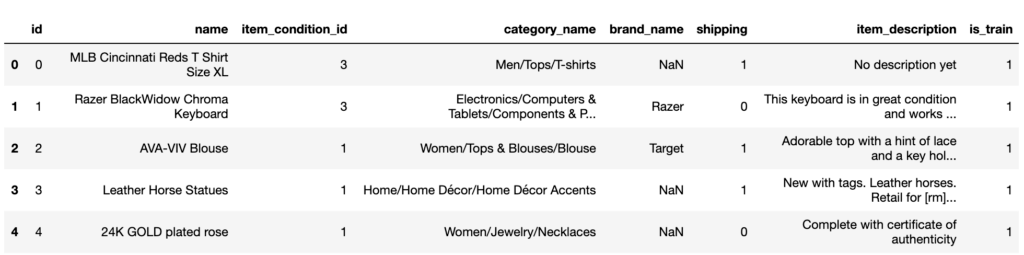
train_test_combine = pd.concat([train.drop([‘price’], axis=1),test],axis=0)
# データの中身を表示
train_test_combine.head()
# train_test_combineの文字列のデータタイプを「category」へ変換
train_test_combine.category_name = train_test_combine.category_name.astype('category')
train_test_combine.item_description = train_test_combine.item_description.astype('category')
train_test_combine.name = train_test_combine.name.astype('category')
train_test_combine.brand_name = train_test_combine.brand_name.astype('category')
# combinedDataの文字列を「.cat.codes」で数値へ変換
train_test_combine.name = train_test_combine.name.cat.codes
train_test_combine.category_name = train_test_combine.category_name.cat.codes
train_test_combine.brand_name = train_test_combine.brand_name.cat.codes
train_test_combine.item_description = train_test_combine.item_description.cat.codes
# データの中身とデータ形式を表示
train_test_combine.head()
train_test_combine.dtypes
id int64
name int32
item_condition_id int64
category_name int16
brand_name int16
shipping int64
item_description int32
is_train int64
dtype: object
# trainのユニークな値を確認
train.apply(lambda x: x.nunique())
# testの一意値を確認
test.apply(lambda x: x.nunique())
# 「is_train」のフラグでcombineからtestとtrainへ切り分ける
df_test = train_test_combine.loc[train_test_combine['is_train'] == 0]
df_train = train_test_combine.loc[train_test_combine['is_train'] == 1]
# 「is_train」をtrainとtestのデータフレームから落とす
df_test = df_test.drop([‘is_train’], axis=1)
df_train = df_train.drop([‘is_train’], axis=1)
# df_trainへpriceを戻す
df_train['price'] = train.price
# priceをlog関数で処理
df_train[‘price’] = df_train[‘price’].apply(lambda x: np.log(x) if x>0 else x)
# df_trainを表示
df_train.head()
4. 実行
予測の実行
今回は予測にランダムフォレストを使ってみたいと思います。前回の記事*で使用した決定木よりも性能のよい識別・予測が できるものとなっています。
# x = price以外の全ての値、y = price(ターゲット)で切り分ける
x_train, y_train = df_train.drop(['price'], axis=1), df_train.price
# モデルの作成
m = RandomForestRegressor(n_jobs=-1, min_samples_leaf=5, n_estimators=200)
m.fit(x_train, y_train)
# スコアを表示
m.score(x_train, y_train)
![]()
Kaggleにアップロード
今回のメルカリ価格提案チャレンジはカーネルでの提出を行わないといけないため、後日カーネルを作成してKaggleにアップロードしたいと思います。
5. まとめ
今回は、カーネルも参考にして進めて行きました。
カーネルでは、特徴量を割り出すためにデータセットをグラフにして分かりやすくしているものが多くとても参考になりました。今後は、機械学習についてだけではなく特徴量エンジニアリングも学んで行き、良い特徴量を割り出すための技術も学んでいきたいと思います。