










イケていないデータでも最善を尽くすクエリ作成(SplitString)
おはようございます。エンジニアの片岡です。
今回は業務で直面したイケていないデータと、それにより起きた課題にどう対応していったかについて記載していきます。
あるあるだな~と思いながら見ていただければ嬉しいです。
1. 遭遇した課題
こんな感じの大量のデータがあり、チーム2に所属するユーザーをすべて抽出したいという局面に遭遇しました。
| ユーザー番号 | 名前 | 所属 |
| A001 | Aさん | チーム1, チーム2, チーム3 |
| A002 | Bさん | チーム2, チーム4 |
| A003 | Cさん | チーム1, チーム2 |
少しでも勉強されている皆さんならこう思われていることでしょう。
「なんでこんなデータの持ち方にしたんや」「まずはデータ構造の見直しからだ」
と。
しかし業務上こういうデータに遭遇することは多々ありますし、データの持ち方から見直しているコストもなく、締め切りは間近。
かといって、数万行あるデータに
WHERE [所属] LIKE ‘%チーム2%’
なんてやろうものなら実行時間が大変なことになってしまいます。
皆さんならどのように対処するでしょうか?
2. 最善を目指す解決策
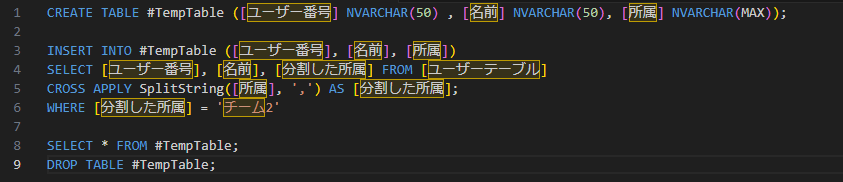
このようになりました。
1行目:一次テーブルを用意して
3~6行目:「所属」を「,」で分割して1行1行のデータにし、そのデータでWHEREの絞り込みをかけ「チーム2」の行だけを一次テーブルにINSERT
8行目:取得したデータを表示
9行目:一次テーブルを削除
となっています。
※一次テーブルに入れているのは、実業務ではこの後いろいろなテーブルを連結して情報を出力していたためです
一度「,」で分割することによりデータをまともな形にし、負荷の高い部分一致検索を使わずにデータを抽出しています。
これによりぐっとクエリの実行時間を減らすことに成功しました。
3. 伝えたいこと
いかがだったでしょうか?
少しでも正規化の知識のある方であれば、「そもそもユーザーテーブルと所属テーブルに分けておくべきだ」というのは分かると思います。
もちろんそれが理想で間違いのない意見であると思いますが、仕事ですのでそうも言ってられない局面というのは必ず現れます。
そもそもの課題に対して文句を言っているだけでは意味がなく、この状況でどうするのが最もよい策なのか?を考えながら要望を実現していくのが我々エンジニアの理想の形だと考えます。
自分が設計を行う際にはこんなゴミみたいなものは作らないぞ!と深く心に刻みながら、今日もタスクをこなしていきましょう。