











「AIの活用:最近の話題」
1. はじめに
こんにちは。プロダクト企画室の関根です。テックブログ初投稿です。
近年、AIの活用が話題に上り始めてからその勢いは衰えることを知らず、今年に入ってからも活発に議論が広がっています。
AIの冬の時代を経験してきた私にとっては、現在のAIの性能やポテンシャルは隔世の感であり、昔から長年AIが活用される未来を思い描いてきたため、とてもエキサイティングな時代に生きていることを実感しています。
2. AIの昔と今
昔からAIは役に立たないと良く言われて来ましたが、アルゴリズムの改善が精度1%の向上を達成しても実用化には程遠いという状況でした。
AIの冬の時代、アカデミアではニューラルネットの様な非線形なシステムを扱うことは、そのモデルから出力される結果が何故良かったのか、論理的な考察も理由付けをすることも難しかったため、研究テーマとしても敬遠されていました。
AIの春の息吹を感じ始めたのはコンピューティング能力の向上もさることならがら、WEBにあるビッグデータを使えることとディープラーニング等を用いた大規模統計モデルを構築出来るようになったためです。
それまで研究室のクローズドな環境で実験されたきたモデルはWEBの多様なデータを取り込み、アルゴリズムを洗練させることで一部のタスクでは実用が見えるレベルに昇華しました。
そして生成AI時代に入り、最近ではモデル性能の向上が非連続に起きている印象を受けています。
その社会適用やAGI(汎用人工知能)の実現という意味ではまだ課題も多く発展の途上ではありますが、昨今の非連続なブレークスルーを考慮すると、AIによる社会変革も遠くない将来、さらに大きな波がやってくる可能性も否定出来ません。
一般企業での活用でも多くは現状既製のLLMを単に利用するところから抜け出せていない状況ですが、今後は現状のLLMの特性と限界を把握し、クライアントの要求を満たすような各種技術と組み合わせることが重要な点として認識が広がっていくと思います。
LLM(大規模言語モデル)は学習データから構築されたモデルで確率統計的に予測されたトークンを出力をすることには長けていますが、分析解析的な能力や論理展開力には限界があり、ここの課題を埋めるような各種技術開発とLLMとの連携が大事になってくるでしょう。
それに合わせてLLM自体の改良や提案も進んでいくものと思われます。LLMの改善技術も特定ドメイン知識の吸収や、アライメントと呼ばれる特定生成トピックの抑制、低ビット学習等のモデルサイズの削減など多岐に渡ります。
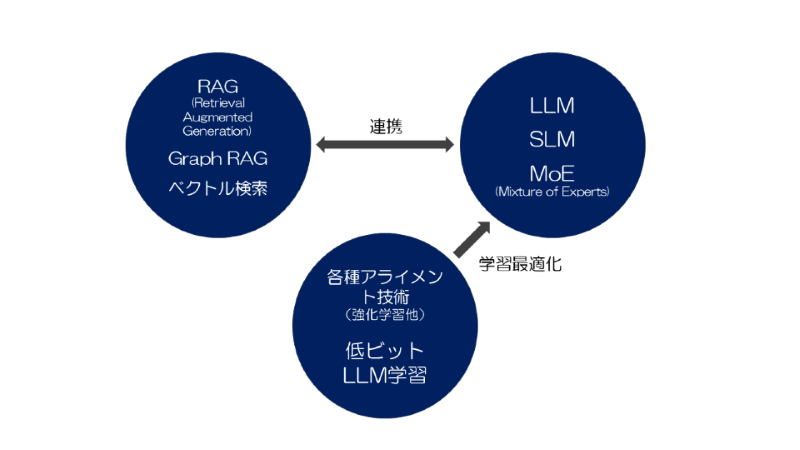
3. RAG(Retrieval Augmented Generation)について
差別化を図る技術を構築するという意味では、RAGによる、外部の言語リソースと連携した適切な生成技術やファインチューニングに代表されるように、外部の言語リソースを付加し、従来のLLMには答えられないドメインに特化した生成を行うモデルを構築することが注力されていくでしょう。
RAGはLLMの拡張として用いられ、その構成はデータストアとインデックスを有する検索器からなります。データストアはLLMの外部の知識源であり文章の集合(例えば企業内ドキュメント)となります。データ形式としてよくあるのはベクトル埋め込み形式でChromaDBなどのベクトルデータベースで管理されます。
実際の検索処理はデータストアと同じ形式のクエリを用いて最近傍探索等の類似度検索が行われます。最近傍探索の方法としては2つのベクトル間の距離を全ての対象ベクトルに対して1つずつ計算していく線形探索が最も基本的ですが、線形探索では計算量がO(N)(Nに比例した計算量)となり時間が掛かるため、近似的に探索を行う効率的手法が用いられます。
OSSとして利用出来る最近傍探索ライブラリは「Faiss」や「Voyager」が有名です。
RAGの利点はLLMに追加の学習を必要とせず、LLMの知識を補足するだけでなく、最新の知識がLLMに反映されるまでのタイムラグを補ったり、LLM固有のハルシネーション(※1)を抑制するといった点にもあります。
良い事の多そうなRAGですが、課題もあります。文章をチャンクにしてベクトル化し検索を掛けるベクトル検索や全文検索では解釈される意図にヒットしない場合もあり、結果をLLMに投げても適切な回答が返せないこともありました。
単純なベクトル探索ではインサイトを作るための横断的な情報が必要であったり、全体的意味論的な理解をする場合には能力を発揮しにくいという側面があります。
2024年2月にMicrosoft Researchから提案されたGraphRAGは「トリプル」「ノード」「エッジ」から構成されるナレッジグラフとRAGを組み合わせたもので、LLMが得意とする文章要約機構をインデクシングに組み込むことで、質問に対する柔軟な回答力を獲得しています。
単に既存のナレッジグラフを用いるのではなくLLMにナレッジグラフを生成させる点が秀逸です。
以下の図では「W2株式会社」「東銀座」がエンティティとなり、「本社」がエンティティ間の関係性を表しています。
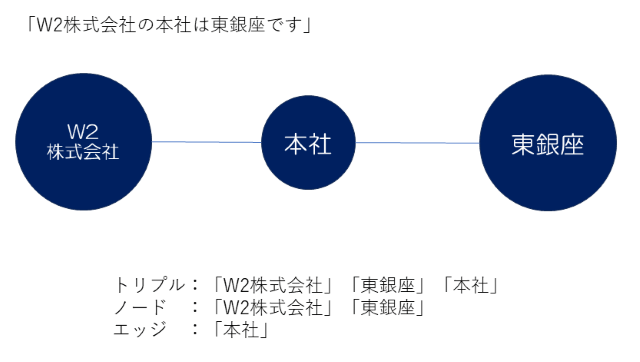
トリプル形式のデータはLLMに文章を入力してエンティティーとその関係性を求めるようにプロンプト指示を行うことによって得られます。
グラフデータベースはNeo4jで、フレームワークはLangChainで試せるので興味のある方は試してみてはいかがでしょうか。
RAGの技術は日々進歩しており、まだ他にも面白い提案がなされていますが、ここで全て紹介することは出来ないので、またの機会で紹介したいと思います。
4. MoE(Mixture of Experts)について
学習と推論の効率化という点で、MoEも知っておくべき重要な技術です。MoEはLLMを構成する要素で、複数のサブモデル(トランスフォーマーの一部)をそれぞれ個別の専門家(Experts)として扱い、ゲーティングと呼ばれる機構を介して自動ルーティングによりクエリを適切なサブモデルに振り分ける機構です。
Expertsは互いに独立していて入力データに応じて必要なExpertsのみが活性化されるため計算が効率的に行なわれ、複数のExpertsの出力が組み合わさることにより単一のモデルより高い性能が達成できるといった特徴を持っています。
Expertsの説明として「金融のエキスパート」とか「政治のエキスパート」といった説明がされることもあります。これはイメージをつかむのには良いのですが、内部動作を説明するにはいささか不正確で、実際はもっと小さなトークン毎に複数のエキスパートが対応するので誤解の無いよう注意したいところです。
MoEのアーキテクチャには大きく分けて密MoEと疎MoEの2つあり、密MoEでは入力トークン列を全てのFFN(フィードフォワードネットワーク)に振り分けるもの、疎MoEは入力トークン列を少数のFFNに振り分けるものとなります。疎MoEの方が計算効率は高いですが、適切なルーティングを行う必要があるという難しさがあります。
この辺りはNVIDIAの技術ブログにも説明がありますので詳しく知りたい方はご参照ください。
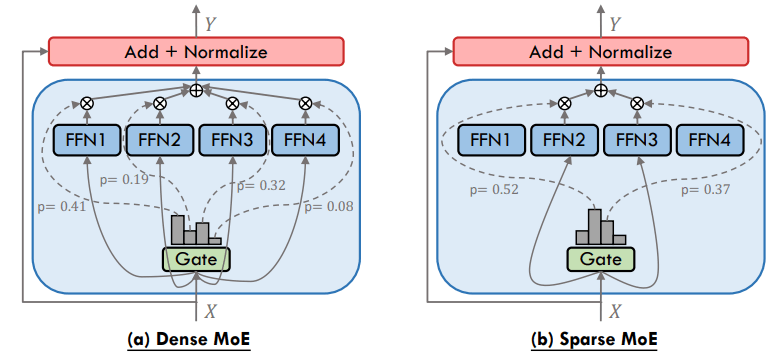
トランスフォーマーベースのLLMではFFNがパラメータ数の大部分を占めていることからエキスパートに振り分けることで実効的なパラメータ数を削減できることもMoEの特徴でしょう。
ちなみに最近注目を浴びたDeep SeekもMoEに特色を出しており、Deep Seek V3ノートの記事によるとマルチヘッドアテンション機構(※2)の後段に疎と密のハイブリッドなMoEを配置していることが分かります。
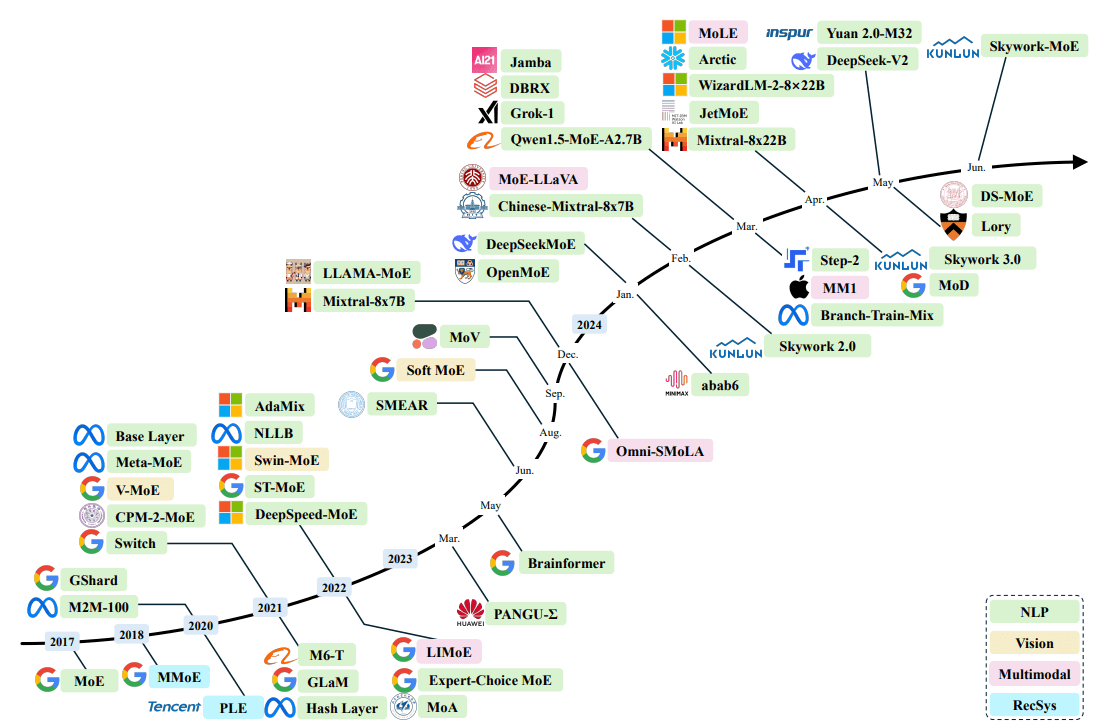
MoEの歴史を振り返ると2017年にGoogleが発表したことから始まっており、適用領域は自然言語処理が主要ですが、ビジョン、マルチモーダル、レコメンドと幅広い範囲に適用されてきました。
最近でも注目されているMoEですが、構造が複雑で学習が不安定になるという課題やルーティングアルゴリズムの改善、また疎MoEの場合は振り分けられたエキスパートでの計算の偏りにより負荷分散方法の改善が必要になることもあり、これからの研究でも解決が望まれます。
また学習と推論が高効率ということは通常のLLMよりも小~中規模な言語モデルであればアプリケーションユーザーに近い立場でも現実的なGPUリソースで特化モデルを開発出来る可能性を秘めており、個人的にはこの点においても興味がある所です。
そのほかにも各種LLMの特性を把握し、それらを使い分けたり、ChatGPTに代表されるクローズドなモデルの利用と蒸留(※3)が可能なオープンなモデルの利用を使い分けることも重要になっていくと思います。
5. 最後に
ドメイン特化のモデルを学習するためのクローズドなデータの活用や、提供サービスを通じて特定の言語資源を獲得することもAI領域における企業競争力の源泉になっていくと思われます。
EC事業においてもそれは例外ではなく、ECサイトに来る前後のお客様のお問い合わせに対して適切に応答することはお客様とのエンゲージメントを高め、お客様に寄り添った購買体験を提供していくために大切なことです。
EC事業の中では商品説明文やキャッチーなフレーズの生成、ブログ等の発信コンテンツの生成、SEO情報生成、事業推進のKPIを読み取り示唆を与える、などAIの応用は多岐に渡り、適切な利用技術は事業価値提供のベースでありKSFになると考えています。
課題も色々多いですが、AIブームの過熱に踊らされないように気を付けたいですね。AIの本質と特性、アルゴリズムを理解し、AIが得意な所はAIに、AIの中でもLLMに任せるところ、その他の技術で補うところなど、さらに機械学習が得意な所は機械学習に任せるといったように状況に合わせて最適なソリューションを提供できるようにキチンと地に足を付けて取り組んでいきたいと思います。
====
W2ではAIや機械学習を活用したPoCサービスを提供しています。「AIを業務に取り入れて業務効率化を図りたい」、「新しいEC事業を創出したい」といった思いをお持ちの事業者様、AIを活用したい全ての皆様と二人三脚で未来を創っていきたいと考えています。EC業界でトップレベルのAI技術を活用してみませんか?ご興味がありましたらお気軽にお問い合わせいただければ幸いです。
(※1) ハルシネーション:生成AIが事実に基づかない情報や存在しない情報を生成してしまう現象。トレーニングデータに偏りがある場合に発生しがちである。
(※2)マルチヘッドアテンション機構:入力トークン埋め込みをキー・バリューの重みづけ和として出力トークン埋め込みに変換する自己アテンション機構を複数に適用して表現力を高めた仕組み
(※3) 蒸留:大規模言語モデル(LLM)の知識や能力を、より小型で効率的なモデルに転移させる技術。この手法により、元の大規模モデルの性能をできるだけ維持しながら、計算リソースやメモリ使用量を削減することが可能になる。