













ノウハウ
ブログ
物体検知アルゴリズムのYOLOv3を試してみる(続き)
目次
はじめに
皆さん、こんばんにちは!みやもとです。
今回は続編!「物体検知アルゴリズムのYOLOv3を試してみる」の続きを行っていこうと思います。前回は物体検知アルゴリズムと言っても写真を行っただけでしたが、今回はカメラでYOLOv3を試すことにしてみます。
試すと言っても、自分でコードを一から書いていくのは時間がかかるため、お試し版としてちょうど良いソースコードがGitHubに上がっていたので、それで試していきたいと思います。
環境は、前回作成したconda環境を利用していきます。
では、GitHubからクーロンを行っていきたいと思います。
1.物体検知のお試し
(yolo_v3) git clone https://github.com/ayooshkathuria/pytorch-yolo-v3.git GitHubからクーロンを行ったら、次に学習済みのモデルをこちらも下記のコマンドでダウンロードしていきます。(yolo_v3) cd pytorch-yolo-v3(yolo_v3) wget https://pjreddie.com/media/files/yolov3.weights 次にカメラを起動させるために必要なライブラリも入れておきます。(yolo_v3) pip install torch===1.4.0 torchvision===0.5.0 -f https://download.pytorch.org/whl/torch_stable.html 下記のコマンドを実行するとカメラが起動して物体検知が行えるようになります。(yolo_v3) python cam_demo.py 実際に動かしたのが下記となります。
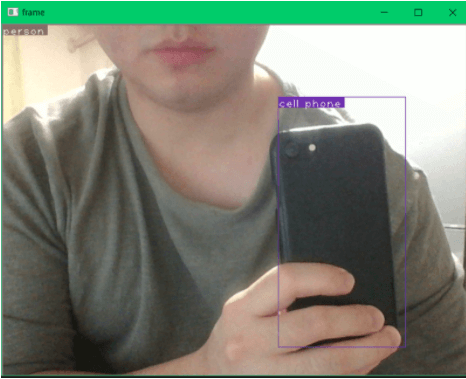
どのように検知されるのかを確認しましたが、顔半分であっても「person」と認識され人間として感知されています。そして私のiPhoneは真っ黒な裏側しか映っていなくても、ちゃんと「cell phone」とスマートフォンとして認識されているようです。
GitHubからクーロンしたソースはそのまま動かなかったので修正したソースを記載しておきます。
<span class="token keyword">from</span> __future__ <span class="token keyword">import</span> division
<span class="token keyword">import</span> time
<span class="token keyword">import</span> torch
<span class="token keyword">import</span> torch<span class="token punctuation">.</span>nn <span class="token keyword">as</span> nn
<span class="token keyword">from</span> torch<span class="token punctuation">.</span>autograd <span class="token keyword">import</span> Variable
<span class="token keyword">import</span> numpy <span class="token keyword">as</span> np
<span class="token keyword">import</span> cv2
<span class="token keyword">from</span> util <span class="token keyword">import</span> <span class="token operator">*</span>
<span class="token keyword">from</span> darknet <span class="token keyword">import</span> Darknet
<span class="token keyword">from</span> preprocess <span class="token keyword">import</span> prep_image<span class="token punctuation">,</span> inp_to_image
<span class="token keyword">import</span> pandas <span class="token keyword">as</span> pd
<span class="token keyword">import</span> random
<span class="token keyword">import</span> argparse
<span class="token keyword">import</span> pickle <span class="token keyword">as</span> pkl
<span class="token keyword def">def</span> <span class="token function">get_test_input</span><span class="token punctuation">(</span>input_dim<span class="token punctuation">,</span> CUDA<span class="token punctuation">)</span><span class="token punctuation">:</span>
img <span class="token operator">=</span> cv2<span class="token punctuation">.</span>imread<span class="token punctuation">(</span><span class="token string">"imgs/messi.jpg"</span><span class="token punctuation">)</span>
img <span class="token operator">=</span> cv2<span class="token punctuation">.</span>resize<span class="token punctuation">(</span>img<span class="token punctuation">,</span> <span class="token punctuation">(</span>input_dim<span class="token punctuation">,</span> input_dim<span class="token punctuation">)</span><span class="token punctuation">)</span>
img_ <span class="token operator">=</span> img<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">:</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">.</span>transpose<span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
img_ <span class="token operator">=</span> img_<span class="token punctuation">[</span>np<span class="token punctuation">.</span>newaxis<span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token operator">/</span><span class="token number">255.0</span>
img_ <span class="token operator">=</span> torch<span class="token punctuation">.</span>from_numpy<span class="token punctuation">(</span>img_<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">float</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
img_ <span class="token operator">=</span> Variable<span class="token punctuation">(</span>img_<span class="token punctuation">)</span>
<span class="token keyword">if</span> CUDA<span class="token punctuation">:</span>
img_ <span class="token operator">=</span> img_<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> img_
<span class="token keyword def">def</span> <span class="token function">prep_image</span><span class="token punctuation">(</span>img<span class="token punctuation">,</span> inp_dim<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token triple-quoted-string string">"""
Prepare image for inputting to the neural network.
Returns a Variable
"""</span>
orig_im <span class="token operator">=</span> img
dim <span class="token operator">=</span> orig_im<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">,</span> orig_im<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span>
img <span class="token operator">=</span> cv2<span class="token punctuation">.</span>resize<span class="token punctuation">(</span>orig_im<span class="token punctuation">,</span> <span class="token punctuation">(</span>inp_dim<span class="token punctuation">,</span> inp_dim<span class="token punctuation">)</span><span class="token punctuation">)</span>
img_ <span class="token operator">=</span> img<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">:</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">.</span>transpose<span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">.</span>copy<span class="token punctuation">(</span><span class="token punctuation">)</span>
img_ <span class="token operator">=</span> torch<span class="token punctuation">.</span>from_numpy<span class="token punctuation">(</span>img_<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">float</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>div<span class="token punctuation">(</span><span class="token number">255.0</span><span class="token punctuation">)</span><span class="token punctuation">.</span>unsqueeze<span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> img_<span class="token punctuation">,</span> orig_im<span class="token punctuation">,</span> dim
<span class="token keyword def">def</span> <span class="token function">write</span><span class="token punctuation">(</span>x<span class="token punctuation">,</span> img<span class="token punctuation">)</span><span class="token punctuation">:</span>
c1 <span class="token operator">=</span> <span class="token builtin">tuple</span><span class="token punctuation">(</span>x<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">:</span><span class="token number">3</span><span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token builtin">int</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
c2 <span class="token operator">=</span> <span class="token builtin">tuple</span><span class="token punctuation">(</span>x<span class="token punctuation">[</span><span class="token number">3</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token builtin">int</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
cls <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span>x<span class="token punctuation">[</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
label <span class="token operator">=</span> <span class="token string">"{0}"</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>classes<span class="token punctuation">[</span>cls<span class="token punctuation">]</span><span class="token punctuation">)</span>
color <span class="token operator">=</span> random<span class="token punctuation">.</span>choice<span class="token punctuation">(</span>colors<span class="token punctuation">)</span>
cv2<span class="token punctuation">.</span>rectangle<span class="token punctuation">(</span>img<span class="token punctuation">,</span> c1<span class="token punctuation">,</span> c2<span class="token punctuation">,</span>color<span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span>
t_size <span class="token operator">=</span> cv2<span class="token punctuation">.</span>getTextSize<span class="token punctuation">(</span>label<span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>FONT_HERSHEY_PLAIN<span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span>
c2 <span class="token operator">=</span> c1<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">+</span> t_size<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">3</span><span class="token punctuation">,</span> c1<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">+</span> t_size<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">4</span>
cv2<span class="token punctuation">.</span>rectangle<span class="token punctuation">(</span>img<span class="token punctuation">,</span> c1<span class="token punctuation">,</span> c2<span class="token punctuation">,</span>color<span class="token punctuation">,</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span>
cv2<span class="token punctuation">.</span>putText<span class="token punctuation">(</span>img<span class="token punctuation">,</span> label<span class="token punctuation">,</span> <span class="token punctuation">(</span>c1<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">,</span> c1<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">+</span> t_size<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">4</span><span class="token punctuation">)</span><span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>FONT_HERSHEY_PLAIN<span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token number">225</span><span class="token punctuation">,</span><span class="token number">255</span><span class="token punctuation">,</span><span class="token number">255</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">return</span> img
<span class="token keyword def">def</span> <span class="token function">arg_parse</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token triple-quoted-string string">"""
Parse arguements to the detect module
"""</span>
parser <span class="token operator">=</span> argparse<span class="token punctuation">.</span>ArgumentParser<span class="token punctuation">(</span>description<span class="token operator">=</span><span class="token string">'YOLO v3 Cam Demo'</span><span class="token punctuation">)</span>
parser<span class="token punctuation">.</span>add_argument<span class="token punctuation">(</span><span class="token string">"--confidence"</span><span class="token punctuation">,</span> dest <span class="token operator">=</span> <span class="token string">"confidence"</span><span class="token punctuation">,</span> <span class="token builtin">help</span> <span class="token operator">=</span> <span class="token string">"Object Confidence to filter predictions"</span><span class="token punctuation">,</span> default <span class="token operator">=</span> <span class="token number">0.25</span><span class="token punctuation">)</span>
parser<span class="token punctuation">.</span>add_argument<span class="token punctuation">(</span><span class="token string">"--nms_thresh"</span><span class="token punctuation">,</span> dest <span class="token operator">=</span> <span class="token string">"nms_thresh"</span><span class="token punctuation">,</span> <span class="token builtin">help</span> <span class="token operator">=</span> <span class="token string">"NMS Threshhold"</span><span class="token punctuation">,</span> default <span class="token operator">=</span> <span class="token number">0.4</span><span class="token punctuation">)</span>
parser<span class="token punctuation">.</span>add_argument<span class="token punctuation">(</span><span class="token string">"--reso"</span><span class="token punctuation">,</span> dest <span class="token operator">=</span> <span class="token string">'reso'</span><span class="token punctuation">,</span> <span class="token builtin">help</span> <span class="token operator">=</span>
<span class="token string">"Input resolution of the network. Increase to increase accuracy. Decrease to increase speed"</span><span class="token punctuation">,</span>
default <span class="token operator">=</span> <span class="token string">"160"</span><span class="token punctuation">,</span> <span class="token builtin">type</span> <span class="token operator">=</span> <span class="token builtin">str</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> parser<span class="token punctuation">.</span>parse_args<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> __name__ <span class="token operator">==</span> <span class="token string">'__main__'</span><span class="token punctuation">:</span>
cfgfile <span class="token operator">=</span> <span class="token string">"cfg/yolov3.cfg"</span>
weightsfile <span class="token operator">=</span> <span class="token string">"yolov3.weights"</span>
num_classes <span class="token operator">=</span> <span class="token number">80</span>
args <span class="token operator">=</span> arg_parse<span class="token punctuation">(</span><span class="token punctuation">)</span>
confidence <span class="token operator">=</span> <span class="token builtin">float</span><span class="token punctuation">(</span>args<span class="token punctuation">.</span>confidence<span class="token punctuation">)</span>
nms_thesh <span class="token operator">=</span> <span class="token builtin">float</span><span class="token punctuation">(</span>args<span class="token punctuation">.</span>nms_thresh<span class="token punctuation">)</span>
start <span class="token operator">=</span> <span class="token number">0</span>
CUDA <span class="token operator">=</span> torch<span class="token punctuation">.</span>cuda<span class="token punctuation">.</span>is_available<span class="token punctuation">(</span><span class="token punctuation">)</span>
num_classes <span class="token operator">=</span> <span class="token number">80</span>
bbox_attrs <span class="token operator">=</span> <span class="token number">5</span> <span class="token operator">+</span> num_classes
model <span class="token operator">=</span> Darknet<span class="token punctuation">(</span>cfgfile<span class="token punctuation">)</span>
model<span class="token punctuation">.</span>load_weights<span class="token punctuation">(</span>weightsfile<span class="token punctuation">)</span>
model<span class="token punctuation">.</span>net_info<span class="token punctuation">[</span><span class="token string">"height"</span><span class="token punctuation">]</span> <span class="token operator">=</span> args<span class="token punctuation">.</span>reso
inp_dim <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span>model<span class="token punctuation">.</span>net_info<span class="token punctuation">[</span><span class="token string">"height"</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token keyword">assert</span> inp_dim <span class="token operator">%</span> <span class="token number">32</span> <span class="token operator">==</span> <span class="token number">0</span>
<span class="token keyword">assert</span> inp_dim <span class="token operator">></span> <span class="token number">32</span>
<span class="token keyword">if</span> CUDA<span class="token punctuation">:</span>
model<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
model<span class="token punctuation">.</span><span class="token builtin">eval</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
videofile <span class="token operator">=</span> <span class="token string">'video.avi'</span>
cap <span class="token operator">=</span> cv2<span class="token punctuation">.</span>VideoCapture<span class="token punctuation">(</span><span class="token number">0</span><span class="token operator">+</span>cv2<span class="token punctuation">.</span>CAP_DSHOW<span class="token punctuation">)</span>
<span class="token keyword">assert</span> cap<span class="token punctuation">.</span>isOpened<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token string">'Cannot capture source'</span>
frames <span class="token operator">=</span> <span class="token number">0</span>
start <span class="token operator">=</span> time<span class="token punctuation">.</span>time<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">while</span> cap<span class="token punctuation">.</span>isOpened<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
ret<span class="token punctuation">,</span> frame <span class="token operator">=</span> cap<span class="token punctuation">.</span>read<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> ret<span class="token punctuation">:</span>
img<span class="token punctuation">,</span> orig_im<span class="token punctuation">,</span> dim <span class="token operator">=</span> prep_image<span class="token punctuation">(</span>frame<span class="token punctuation">,</span> inp_dim<span class="token punctuation">)</span>
<span class="token comment"># im_dim = torch.FloatTensor(dim).repeat(1,2) </span>
<span class="token keyword">if</span> CUDA<span class="token punctuation">:</span>
im_dim <span class="token operator">=</span> im_dim<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
img <span class="token operator">=</span> img<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
output <span class="token operator">=</span> model<span class="token punctuation">(</span>Variable<span class="token punctuation">(</span>img<span class="token punctuation">)</span><span class="token punctuation">,</span> CUDA<span class="token punctuation">)</span>
output <span class="token operator">=</span> write_results<span class="token punctuation">(</span>output<span class="token punctuation">,</span> confidence<span class="token punctuation">,</span> num_classes<span class="token punctuation">,</span> nms <span class="token operator">=</span> <span class="token boolean">True</span><span class="token punctuation">,</span> nms_conf <span class="token operator">=</span> nms_thesh<span class="token punctuation">)</span>
<span class="token keyword">if</span> <span class="token builtin">type</span><span class="token punctuation">(</span>output<span class="token punctuation">)</span> <span class="token operator">==</span> <span class="token builtin">int</span><span class="token punctuation">:</span>
frames <span class="token operator">+=</span> <span class="token number">1</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"FPS of the video is {:5.2f}"</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span> frames <span class="token operator">/</span> <span class="token punctuation">(</span>time<span class="token punctuation">.</span>time<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">-</span> start<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
cv2<span class="token punctuation">.</span>imshow<span class="token punctuation">(</span><span class="token string">"frame"</span><span class="token punctuation">,</span> orig_im<span class="token punctuation">)</span>
key <span class="token operator">=</span> cv2<span class="token punctuation">.</span>waitKey<span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> key <span class="token operator">&</span> <span class="token number">0xFF</span> <span class="token operator">==</span> <span class="token builtin">ord</span><span class="token punctuation">(</span><span class="token string">'q'</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">break</span>
<span class="token keyword">continue</span>
output<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span> <span class="token operator">=</span> torch<span class="token punctuation">.</span>clamp<span class="token punctuation">(</span>output<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token number">0.0</span><span class="token punctuation">,</span> <span class="token builtin">float</span><span class="token punctuation">(</span>inp_dim<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token operator">/</span>inp_dim
<span class="token comment"># im_dim = im_dim.repeat(output.size(0), 1)</span>
output<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">,</span><span class="token number">3</span><span class="token punctuation">]</span><span class="token punctuation">]</span> <span class="token operator">*=</span> frame<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span>
output<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">,</span><span class="token number">4</span><span class="token punctuation">]</span><span class="token punctuation">]</span> <span class="token operator">*=</span> frame<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span>
classes <span class="token operator">=</span> load_classes<span class="token punctuation">(</span><span class="token string">'data/coco.names'</span><span class="token punctuation">)</span>
colors <span class="token operator">=</span> pkl<span class="token punctuation">.</span>load<span class="token punctuation">(</span><span class="token builtin">open</span><span class="token punctuation">(</span><span class="token string">"pallete"</span><span class="token punctuation">,</span> <span class="token string">"rb"</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token builtin">list</span><span class="token punctuation">(</span><span class="token builtin">map</span><span class="token punctuation">(</span><span class="token keyword">lambda</span> x<span class="token punctuation">:</span> write<span class="token punctuation">(</span>x<span class="token punctuation">,</span> orig_im<span class="token punctuation">)</span><span class="token punctuation">,</span> output<span class="token punctuation">)</span><span class="token punctuation">)</span>
cv2<span class="token punctuation">.</span>imshow<span class="token punctuation">(</span><span class="token string">"frame"</span><span class="token punctuation">,</span> orig_im<span class="token punctuation">)</span>
key <span class="token operator">=</span> cv2<span class="token punctuation">.</span>waitKey<span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> key <span class="token operator">&</span> <span class="token number">0xFF</span> <span class="token operator">==</span> <span class="token builtin">ord</span><span class="token punctuation">(</span><span class="token string">'q'</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">break</span>
frames <span class="token operator">+=</span> <span class="token number">1</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"FPS of the video is {:5.2f}"</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span> frames <span class="token operator">/</span> <span class="token punctuation">(</span>time<span class="token punctuation">.</span>time<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">-</span> start<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">else</span><span class="token punctuation">:</span>
<span class="token keyword">break
</span>
<span aria-hidden="true" class="line-numbers-rows"><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span><span></span></span>2.まとめ
実際にGitHubからクーロンしてきたソースを実行してみましたが確かに物体検知は精度が良かったですが、動きとして少し遅れて動いてしまっていたためそのまま製品に入れることはできないものでした。しかし、このようなソースコードは見るだけでもとても勉強になります。このソースコードを参考に私なりにカメラを使った物体検知アルゴリズムを組んでいきたいと思います。